In the age of content overload, long-form storytelling from TV series to documentaries requires distillation for different audiences. Whether it's internal execs looking for quick insights or researchers dissecting plot structures, the need for efficient, accurate summarization is growing.
To meet this demand, we built a summarization framework powered by Gemini 1.5 Pro, designed to generate high-quality Plot and Executive Summaries from multi-hour narrative content. In this post, we’ll walk through our multi-stage pipeline that not only handles massive inputs but produces structured, targeted outputs for different stakeholders.
Long-form media often spans hundreds of thousands of words. With LLM token limits being a key bottleneck, designing a summarization system that scales while maintaining context, coherence, and clarity becomes a serious engineering challenge.
That’s where our summarization framework comes in.
At its core, our framework is a two-pass, multi-stage summarization pipeline. It breaks down like this:
Long Summary: Capture the full content with context-aware summarization across multiple chunks.
Plot Summary: Extract a reader-friendly summary with character and event structure.
Executive Summary: Craft a concise, narrative-driven version for high-level stakeholders.
All stages leverage Gemini 1.5 Pro, using a strategy that maximizes input size and contextual depth.
A key technical challenge in long-form summarization is context window size. Most LLMs struggle with maintaining coherence across large documents because they simply can't "see" the full input all at once.
That's where Gemini 1.5 Pro stands out.
Gemini 1.5 Pro offers a production-grade context window of up to 1 million tokens, a significant leap from the 32K token limit of earlier models like Gemini 1.0. This capacity unlocks major advantages for summarizing long-form content:
1 hour of video
11 hours of audio
Codebases with 30,000+ lines
Over 700,000 words of text
In practical terms, this means we can feed entire seasons of a show or complete transcripts into the model with minimal splitting, maintaining much higher narrative continuity and semantic accuracy than would be possible with smaller models.
By building our summarization framework around Gemini 1.5 Pro, we ensured that even the most complex, multi-hour stories are handled with the depth and fidelity they deserve, all in a single inference cycle or in fewer context hops.
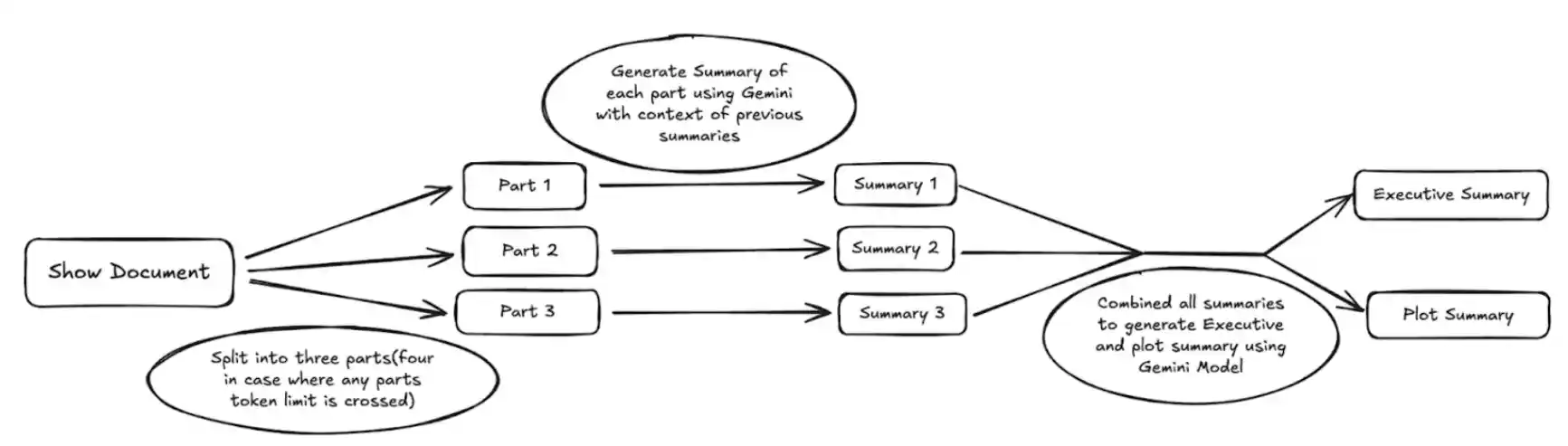
When dealing with long-form content like full-season transcripts or extended narratives, the primary bottleneck in LLM processing is input context length. Although Gemini 1.5 Pro supports up to 1 million tokens per prompt, raw inputs can still exceed this limit. To address this, we implement a hierarchical chunking and summarization loop that ensures:
No prompt exceeds the token threshold.
Cross-part continuity is preserved.
Summarization is performed incrementally but with awareness of preceding context.
Chunking Strategy
We follow a multi-level chunking protocol:
Primary Division:
Split the source material into three logical segments (Part 1, 2, 3) based on total token length and natural content boundaries (e.g., narrative arcs or episodes).
If any part exceeds ~900K tokens (to leave space for prompts/instructions), it is further divided into a fourth segment or recursively chunked into subparts.
Token-Aware Batching:
Use tokenizers (e.g., SentencePiece or the Gemini-compatible tokenizer) to ensure clean segment boundaries without truncating in the middle of sentences or paragraphs.
Each segment is batched such that the combined prompt and content stay well within the 1M token cap.
To ensure temporal coherence and contextual consistency, summarization is performed in a chained fashion:
Step 1.1: Generate summary for Part 1 independently.
Step 1.2: For Part 2, the prompt includes both the content of Part 2 and the generated summary of Part 1.
Step 1.3: For Part 3, include summaries of both Parts 1 and 2 in the prompt as context.
Step 1.4: If Part 4 exists, aggregate all previous summaries and append them as preamble context to the input.
Each step uses a prompt template that explicitly instructs the model to “extend and build upon the previous parts,” enabling a pseudo-memory effect across segments.
Prompt Template:
"You are continuing the summary of a long-form narrative. Here is the summary so far: [previous summaries]. Now summarize the next segment:"
This structure allows us to maintain continuity in tone, theme, and character development, even when summarizing serialized or episodic content.
This sequential, context-aware generation mimics how a human would progressively build understanding.
The final result is a cohesive long summary of approximately 20,000–22,000 words rich in detail and perfect for downstream summarization tasks.
The Plot Summary is designed to serve literary analysis and story structure needs. It reduces the long summary down to ~2,500 words, organized for clarity and narrative flow.
We use the long summary as the base input to ensure consistent voice and content alignment.
Short Summary: High-level view of the entire story.
Character Sketches: Brief bios and arcs of key characters.
Main Literary Events: Plot-driven highlights with causality and consequence.
This structured output ensures the summary isn’t just shorter, but more informative per word.
The Executive Summary is designed for busy executives or decision-makers who need the story’s essence—quickly.
Narrative-driven: Feels like a short story, not a list of events.
Brevity with depth: Around 2,500 words, covering major arcs and characters.
Fluent, coherent, and genre-aligned: Retains the original tone and pacing.
Clarity-first: Avoids jargon or dense prose; clear, concise language.
Once again, the long summary serves as input. We reuse Gemini 1.5 Pro in a second pass, this time with a narrative prompt structure focused on stakeholder comprehension.
Model Used: Gemini 1.5 Pro throughout all stages.
Pipeline Design: Two-pass summarization, first for compression, then for specialization.
Token-Aware Processing: Maximize model throughput with chunk-aware strategies.
Output Range:
Long Summary: ~20,000–22,000 words
Plot Summary: ~2,500 words
Executive Summary: ~2,500 words