Building an AI pipeline that transposes stories across any cultural universe
adaption video
At scale, this gap between translation and true localization becomes a product problem, not just a linguistic one. We’re not adapting a single story, we’re adapting thousands, across markets with distinct cultural expectations, consumption patterns, and narrative norms. A literal translation might be technically correct, but it fails to drive engagement, retention, or emotional resonance with audiences in new geographies. For us, adaptation isn’t a creative luxury, it’s a growth lever. If stories don’t feel native, they don’t perform. That makes cultural transposition, done consistently, systematically, and at scale, central to how we expand into new markets, unlock content supply, and ensure every story lands with the same impact it had in its original form.
Translation gets the words right. Localization gets the world right.
Take The Office, the British workplace comedy that was successfully reimagined for American audiences, or The Departed, Martin Scorsese’s Boston crime thriller adapted from the Hong Kong film Infernal Affairs. In both cases, what made them work for new audiences was not just language. It was the way the entire social and cultural fabric was rebuilt so the story felt native in its new setting.
Any modern LLM can translate a novel in minutes. Feed it Japanese prose, get back English text. The grammar checks out. But something essential is missing. Translation preserves language. Localization preserves experience. When a character in a Japanese novel reaches for onigiri after a long day, a French reader shouldn’t encounter a foreign food item; they should feel the same mundane comfort a tartine provides. When a Korean drama’s protagonist claws through chaebol politics, a Brazilian adaptation needs corporate power structures that hit with the same weight. When an Arabic coming-of-age story hinges on family honor, a German version must find equally high-stakes social fabric.
A well-localized story feels native. The reader forgets they’re reading something that originated in another culture. Characters behave like people they might know. The settings feel like places they’ve visited. That’s the bar.
We built a system that does this. Not for one language pair, but as a general architecture where source language, source culture, target language, and target culture are all parameters. Swap the config values, and the entire cultural universe shifts.
Translation breaks fiction in three dimensions. First, entity consistency: a character named in chapter 1 must carry that exact name through chapter 200, across every nickname, title, and pronoun reference. Second, cultural alignment: you can’t drop a Shinto shrine into suburban Ohio and expect the scene to make sense. The entire cultural fabric must be transposed, not just the words. Third, dependency chains: an estate’s localized name depends on a character’s localized surname, which depends on the target culture’s family naming conventions. One broken link cascades through every downstream reference.
These failures compound. A single inconsistency in chapter 5 (a name spelled differently, a cultural artifact left untranslated) becomes confusion by chapter 50. Readers lose trust. The spell breaks.
We call it the “foreign enclave” problem. Naive translation creates scenes where localized and untranslated elements coexist in the same paragraph: an American character eating at a restaurant in Chicago, but the restaurant serves “mapo tofu” described with Chinese culinary terminology, in a building on a street with a Chinese name. The scene becomes culturally dissonant. It belongs to no world the reader recognizes.
The dependency chain makes this worse than it sounds. Consider a concrete example. A Japanese novel features the Tanaka family. Their estate, “Tanaka-tei,” appears in 40 chapters. Servants refer to the patriarch as “Tanaka-sama.” The family crest appears on invitations, business cards, and a gate inscription. Now localize this for American English. “Tanaka” becomes “Morrison.” But that means “Tanaka-tei” must become “Morrison Manor”, not just the name, but the architectural description shifts from Japanese traditional to American colonial. “Tanaka-sama” becomes “Mr. Morrison.” The crest becomes a monogram. Every one of those 40 chapters must reflect the change, and every reference must agree.
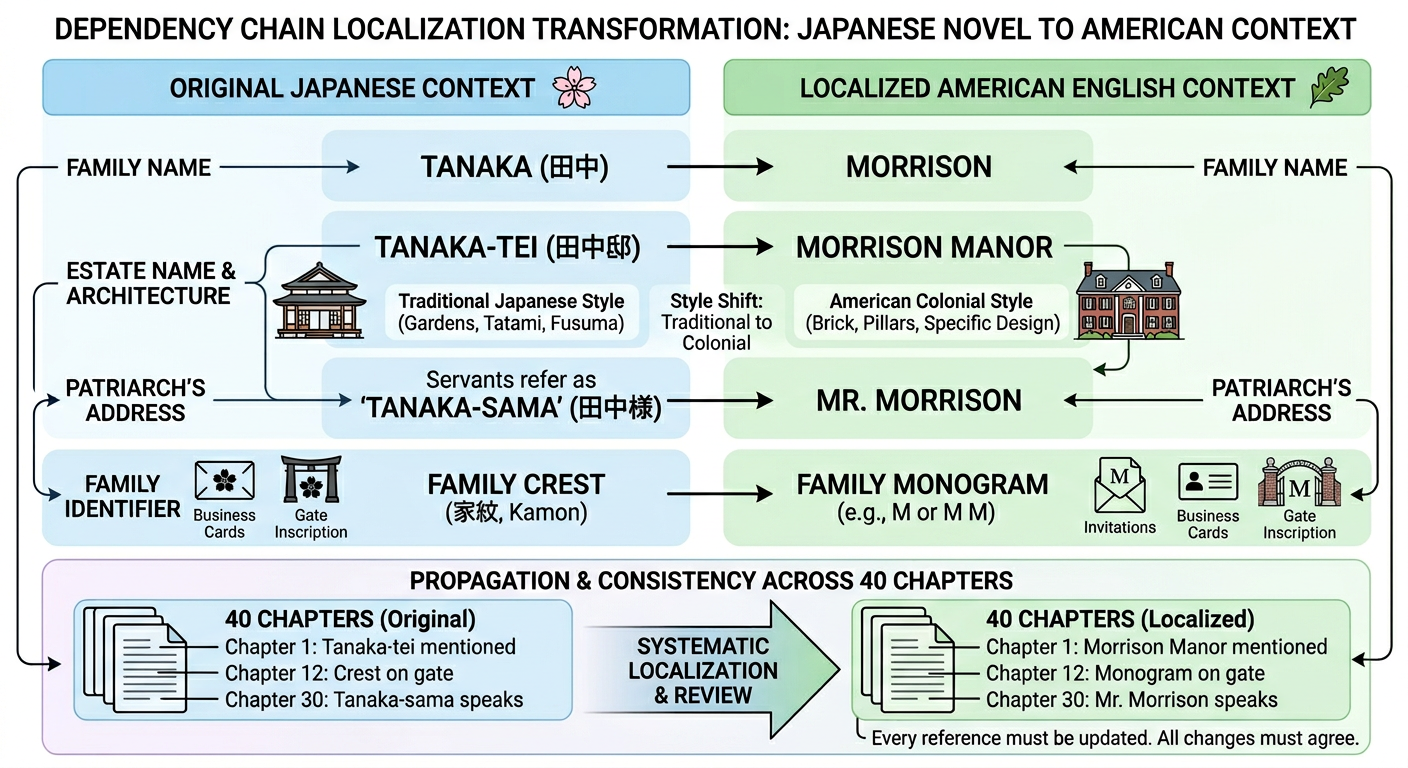
Why can’t you just batch-translate and find-replace? Because the dependencies aren’t string matches. “Tanaka-tei” doesn’t contain the substring “Morrison.” The relationship is semantic, not lexical. A find-replace pass that converts “Tanaka” to “Morrison” will miss “Tanaka-tei” entirely, corrupt “Tanaka-sama” into “Morrison-sama” (mixing cultures), and leave the crest description untouched. You need a system that understands these are all the same family and transposes them as a unified unit.
What if you have 200 such families across 300 chapters? That’s the problem we set out to solve. We’ll follow the Tanaka family through each phase of the pipeline to make the process concrete. The same process applies to any source-target pair, this is just one instance.
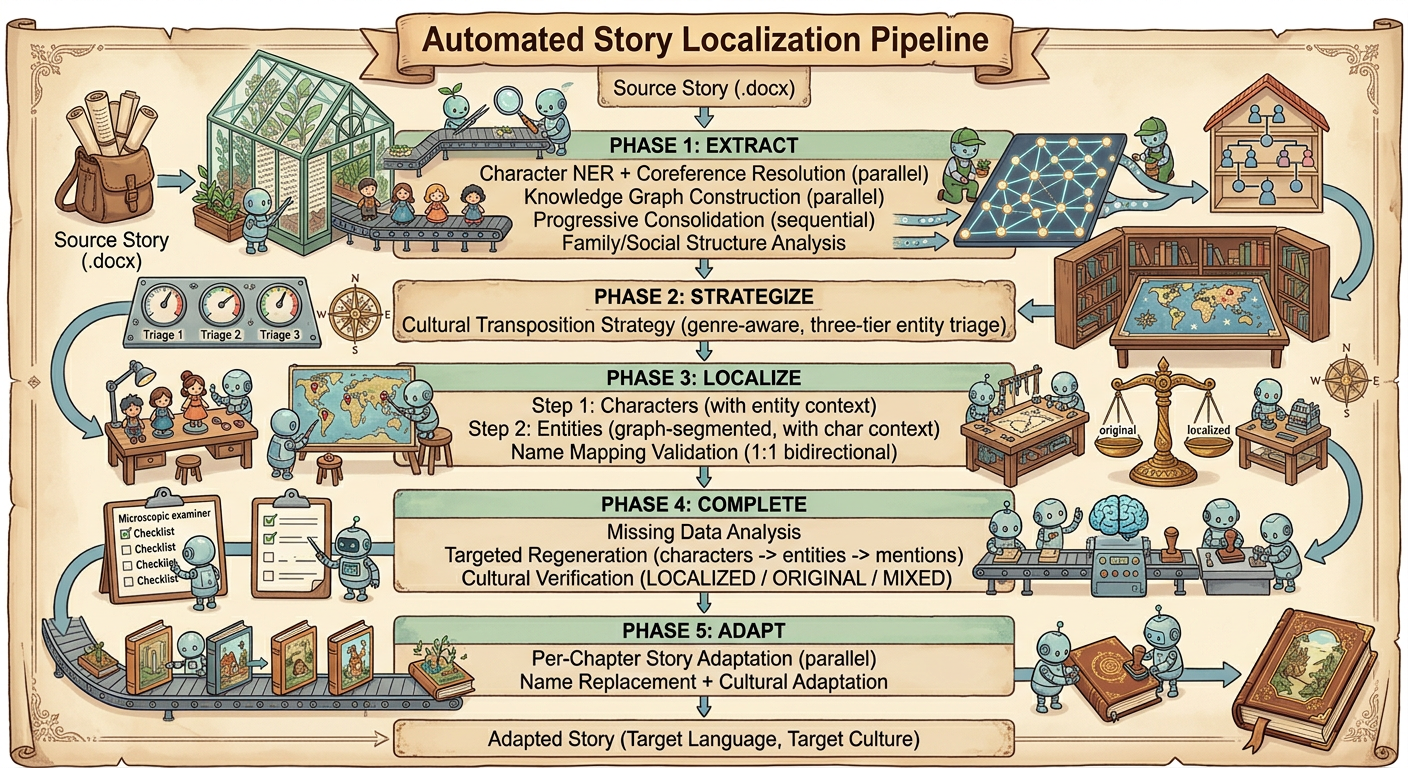
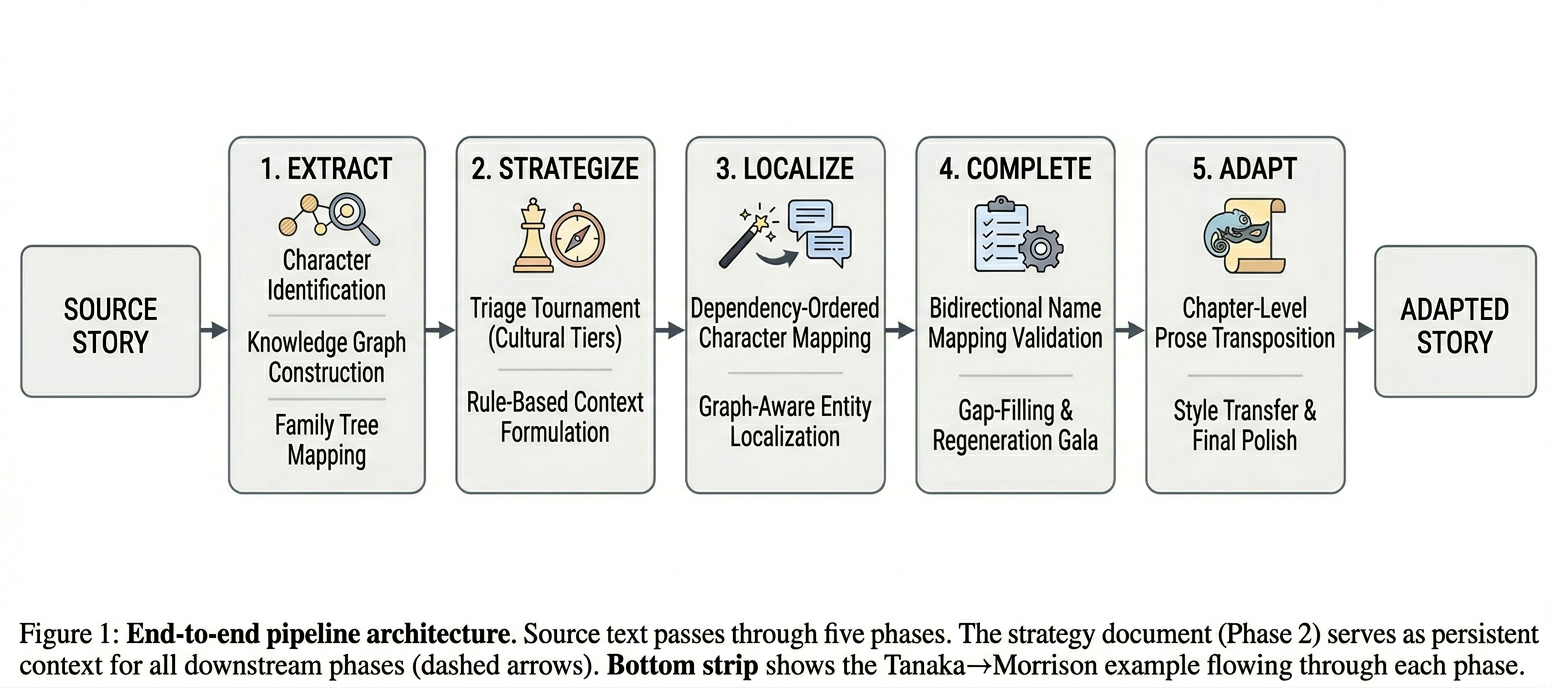
The pipeline runs in five sequential phases, each parallelized internally: Extract, Strategize, Localize, Complete, Adapt.
Extract identifies every character and entity in the source text. Strategize builds a cultural transposition plan before any names change. Localize applies that plan to characters first, then entities, using graph-based community detection to keep related items together. Complete finds and fills gaps through targeted regeneration. Adapt rewrites each chapter in the target culture’s voice, with every localized identity settled. Each phase persists its results, so the pipeline can restart from any point.
Before localizing a story, you need to know who and what is in it.
The extraction phase identifies every character and entity across the full story, then resolves that a pronoun in chapter 50, a nickname in chapter 30, and a formal title in chapter 5 all refer to the same person. A character introduced as “Dr. Yamamoto” in one chapter might be called “Kenji” by his wife, “Dad” by his daughter, “the professor” by students, and “he” in narration. Extraction collapses all of these into a single identity. It also builds a knowledge graph of non-character entities, including locations, organizations, artifacts, cultural concepts, and the relationships between them.
How does this work when the source text could be in any language?
The NER uses LLM-powered extraction, which is language-agnostic by nature, the model reads Japanese, Arabic, Korean, or Chinese without language-specific rules or preprocessing pipelines. The extraction logic itself does not change per language. Where needed, we add targeted prompt-level handling for specific cases, such as explicitly asking the model to detect and correctly process Traditional and Simplified Mandarin scripts during extraction.
Chapters are processed in parallel. Each chapter goes through NER and knowledge graph extraction independently, using LLM-powered coreference resolution. The system identifies canonical names, captures every mention form (formal names, nicknames, titles, kinship terms, pronouns), and distinguishes primary identity mentions from alternative mentions like secret identities or disguises.
The character data model captures this structure. Here’s what it looks like for the patriarch of our Tanaka family:
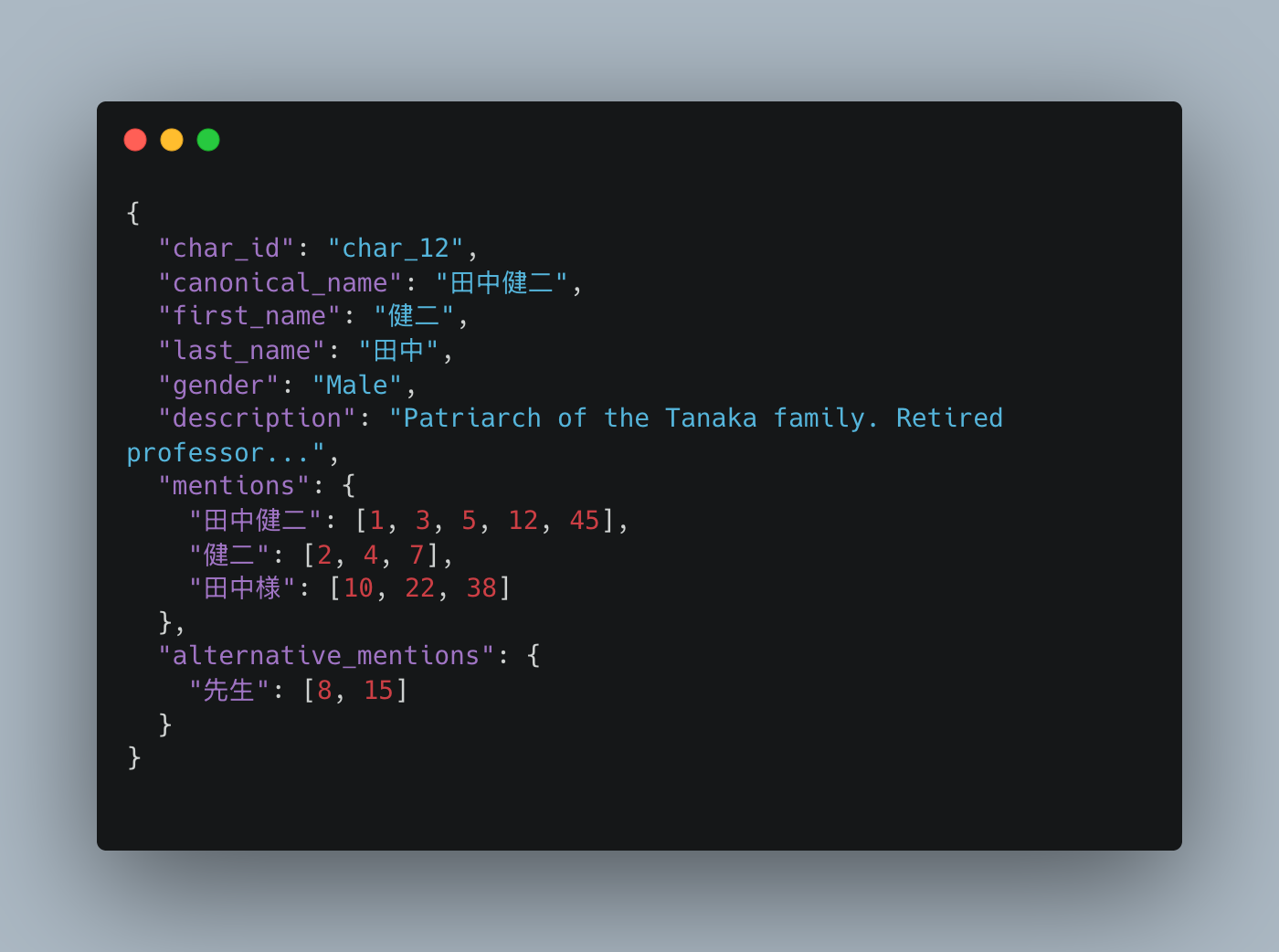
When this character reaches the localization phase, every one of these mentioned forms will need a corresponding target-culture equivalent.
Each key mentioned is a surface form: the exact string that appears in the text. The values are chapter indices where that form occurs. This gives the localization engine a complete map: it knows not just who exists but how they’re referred to and where.
After parallel extraction, progressive consolidation merges chapter-level results into a global character list. This runs sequentially; the LLM decides whether each new cluster matches an existing character or represents someone new, using matching priority: direct name match, then family-plus-title match, then descriptive match. Mentions accumulate across chapters.
The knowledge graph tracks non-character entities with similar precision. Entity types span cultures: locations (a Parisian arrondissement, an Osaka ward, a fictional kingdom), organizations (a Korean chaebol, an Indian business house, a fantasy guild), objects (a ceremonial dagger, a family heirloom, a magical artifact), abstract concepts (the Japanese concept of wa, the Arabic concept of wasta, a magic system’s rules), and cultural keywords – terms so embedded in their source culture that they require special handling during localization.
Each entity also carries dependency metadata: which characters or other entities its name depends on, and the reason for its name. This dependency data becomes critical during localization, when a location named after a family must update if that family’s name changes.
A final pass handles family and social structure analysis: grouping characters by surname, detecting surname changes (marriages, adoptions), and mapping kinship relationships. This structural layer ensures that when one family member’s name is localized, the entire family follows suit.
The system plans before it acts. Before replacing a single name, it generates a comprehensive cultural transposition strategy, a document that maps the entire source cultural universe onto the target. This is the key insight we arrived at through failure: localization is a planning problem, not a search-and-replace problem. Without a strategy, independent localization decisions drift. With one, thousands of decisions stay aligned.
The strategy document becomes a persistent context. Every subsequent LLM call (character localization, entity localization, adaptation) receives the strategy as part of its prompt. It’s the constitution that governs all downstream decisions.
The strategy engine produces fundamentally different plans depending on genre.
For contemporary fiction, the strategy maps real-world social structures. Corporate hierarchies, legal systems, educational institutions, urban geography, all get explicit source-to-target mappings. A Korean drama set in Seoul’s corporate world, localized for an American audience, gets a strategy that maps chaebols to specific types of American conglomerates, Korean honorific hierarchies to American corporate titles, and Gangnam to Manhattan or Buckhead depending on the story’s tone.
For epic fantasy, the engine transposes mythology and magic systems. Source cosmology maps to target-culture mythological traditions. Naming conventions shift to match the target’s fantasy literary expectations. The strategy favors plain, timeless vocabulary, such as Fire over Crimson, Stone over Petric, King over Emperor, to avoid ornate constructions that feel artificial.
Both modes use a three-tier entity triage system:
Tier 1: Preserve and Explain. Used sparingly, for concepts so tied to the plot that replacing them would break the story’s logic. Arabic calligraphy as a plot device – where the visual form of the script drives a mystery, stays as calligraphy, with enough context woven into the prose for the target reader. The Japanese concept of war (social harmony) in a story where its violation is the central conflict gets preserved with naturalistic explanation. This tier is the exception, not the rule.
Tier 2: Analogous Replacement. The source concept has a functional equivalent in the target culture that carries similar weight. Korean chaebols become American tech conglomerates or old-money dynasties. An Indian joint family system maps to an extended Southern American family. A Russian communal apartment (kommunalka) becomes a crowded Brooklyn brownstone with shared spaces. The replacement isn’t a literal translation. It’s a cultural rhyme.
Tier 3: Cultural Replacement. The default tier. The source item is fully replaced with its target-culture counterpart. Japanese onigiri becomes a French tartine. A Russian banya scene becomes an American spa day. Lunar New Year becomes the culturally appropriate celebration for the target setting. The reader should never sense that the item was transposed. It should feel native. The Tanaka estate falls squarely here, every mapping recorded in the strategy document and referenced by every downstream LLM call.
The cardinal rule governing all three tiers: 100% of the source story’s “home culture” must be fully transposed. No half-measures. No scenes where a character lives in an American suburb but eats breakfast from a Korean street vendor, or attends a German university but celebrates Diwali without narrative justification. If a cultural element exists in the source, it either maps to the target culture (Tiers 2 and 3) or is explicitly preserved with context (Tier 1). No element is simply left untouched and unexplained.
The strategy document is typically thousands of words long. It covers naming conventions (given-name-first vs. surname-first cultures), geographic mappings (source cities to target cities with similar socioeconomic profiles), institutional equivalents (education systems, legal systems, corporate structures), and cultural item replacement tables. All of this is generated once, then referenced everywhere. The result is a localization that doesn’t just swap names. It inhabits the target culture completely.
Characters and entities can’t be localized in isolation. A family estate’s name depends on the family’s localized surname. A corporation depends on its founder’s name. A neighborhood depends on the city it belongs to. These dependencies form a directed graph, and if you ignore these relationships, you get contradictions. We split localization into two steps (characters first, then entities) and within the entity step, we use graph community detection to segment related entities into consistent batches. The result: tractable LLM context windows and cross-entity consistency that random batching destroys.
Step 1: Characters with entity context. Characters are localized in batches of 50, with the full entity list provided as read-only context. The LLM sees what entities exist so it can make naming decisions that won’t collide, but it only produces character localizations. Family consistency is enforced through first-name and last-name mapping lists: if two characters share a source surname, they must share a target surname. This constraint is structural, not advisory. The mapping lists are validated after every batch.
Step 2: Entities with character context. Now the localized character list becomes the context, and entities are the production target. This step runs in sub-phases.
Location entities go first. Geographic consistency is foundational. You need settled city and region names before localizing the businesses, schools, and landmarks within them.
Non-location entities are where graph segmentation earns its keep. Why does it beat a flat list? Consider 500 entities from a sprawling fantasy epic being localized for a Spanish audience. Feed all 500 to an LLM and you’ll exceed context limits. Batch them randomly into groups of 50 and you’ll split a magical academy from its professors, its curriculum, and its rival institution – four related concepts landing in four different batches, each localized without awareness of the others. Graph-aware segmentation keeps the academy, its faculty, its courses, and its rivals in the same community. Consistency is structural, not lucky.
The pipeline builds an entity relationship graph using NetworkX, with edges representing co-occurrence, dependency, and semantic relationships. Louvain community detection partitions this graph into segments of related entities. For smaller graphs, Girvan-Newman edge-betweenness provides finer control. Degree-based clustering serves as the final fallback.
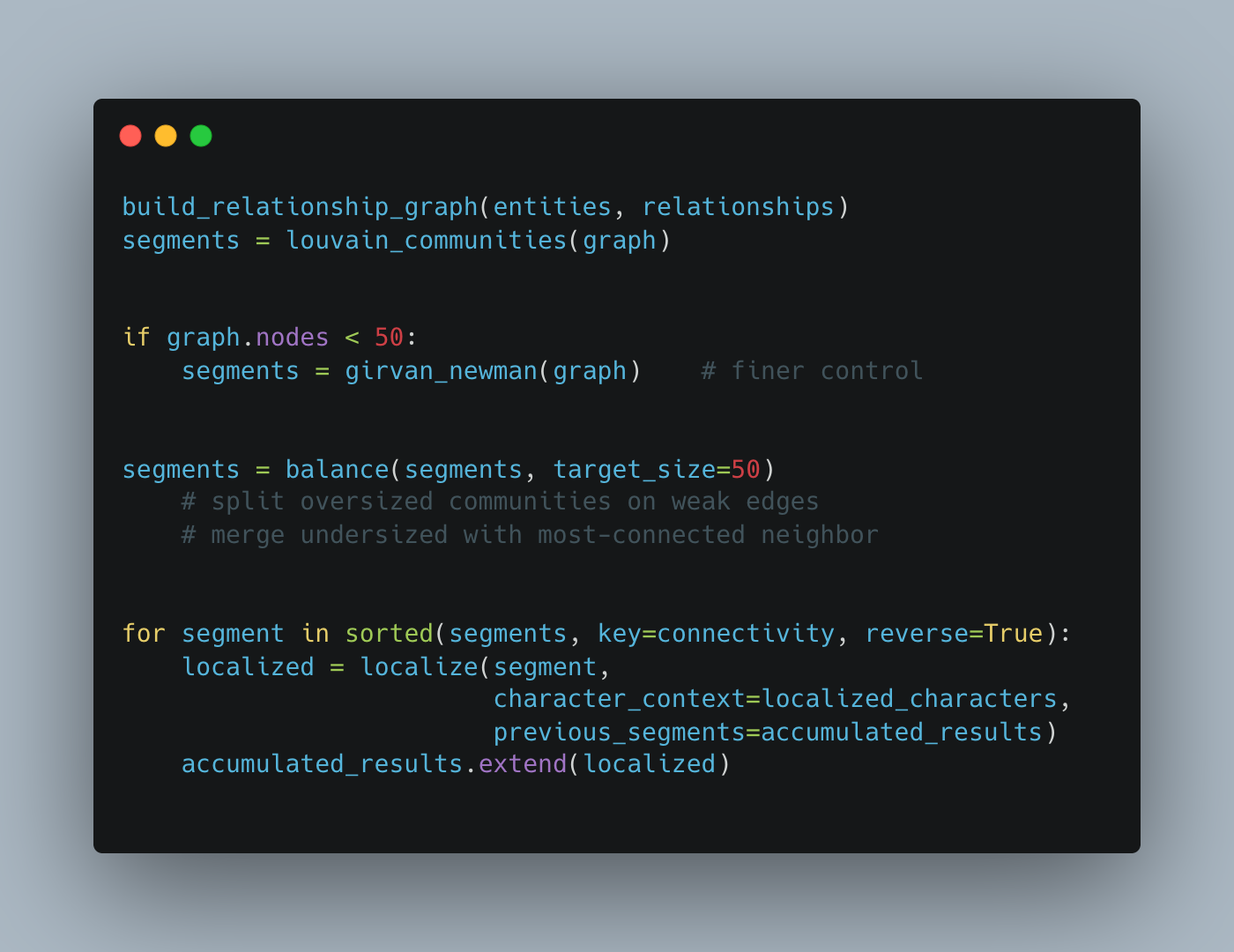
Segment sizes are balanced after detection. Oversized communities get split along internal weak edges. Undersized communities merge with the nearest community. Each segment receives the localized results of all previous segments, so decisions accumulate rather than drift. The ordering is deterministic: segments process from most-connected to least-connected, ensuring that central, high-dependency entities settle first.
The Tanaka family shows why order matters. In Step 1, “田中” localizes to “Morrison.” In Step 2, the entity “田中邸” (Tanaka-tei) can now correctly become “Morrison Manor” because it sees the settled character name. If entities had been localized first, “田中邸” might have become “Tanaka Estate”, mixing source and target cultures in the same name.
Three thousand LLM calls will produce gaps. We don’t reprocess. Instead, the pipeline validates, identifies exactly what’s broken, and surgically regenerates only those items.
Name mapping validation catches two classes of errors: one-to-many (the same source name “Park” mapped to both “Parker” and “Patterson” across batches) and many-to-one (two distinct source names both mapped to “Smith”). Family surname consistency is enforced structurally: shared source surnames must produce shared target surnames. When violations are detected, the LLM corrects them with full character context and the strategy document.
Missing data analysis categorizes every character and entity as completely missing, partially localized, or fully complete. Targeted regeneration runs in dependency order: missing characters first, then entities, then mentions. If “田中様” (Tanaka-sama) was missed but “田中” and “田中邸” correctly mapped to “Morrison” and “Morrison Manor,” regeneration produces “Mr. Morrison”; consistent with the family, not invented in isolation.
A cultural verification pass classifies each item as LOCALIZED, UNIVERSAL, ORIGINAL, or MIXED. “Morrison-sama” instead of “Mr. Morrison” gets flagged as MIXED. That last 2% of untransposed names gets caught before the story ships.
By the time the pipeline reaches adaptation, every character has a settled localized identity and every entity has a target-culture name. The hard decisions are made. Now the system rewrites each chapter in the target culture’s voice.
Adaptation runs chapter-by-chapter in parallel across 12-20 workers. Each chapter goes through multiple passes. First, translation of text & entity replacement: the adapter loads the original mention -> adapted mention mappings and swaps every source-language mention for its localized equivalent. Characters, currency, food, festivals, honorifics, institutions, everything the strategy document flagged for transposition gets rewritten. A scene where the Tanaka family gathers for New Year’s becomes the Morrisons gathering for Thanksgiving. The menu changes. The customs change. The emotional register stays the same. Second, a prose rephrasing pass adjusts sentence rhythm and idiomatic expression so the text reads naturally in the target language. Next, specific language prompts are passed to fine-tune, polish & add nuances such as drama & tension to the adapted text to make it ready for listeners in targeted geographies.
The output is a complete document: every chapter adapted, every name consistent, every cultural reference transposed. The Tanaka family entered as raw Japanese text. They leave as the Morrisons.
Our adaptation engine currently powers localization for 14+ language pairs (source and target), and it's now engineered in a way that we can extend this to any new market or language pair seamlessly.
🇺🇲 US: Translated ENG → ENG US · Mandarin → ENG US · German → English US · Korean → English US
🇩🇪 Germany: English US → German
🇫🇷 France: German → French · English → French
🇮🇳 India (Hindi): English US → Hindi
🇬🇧 UK: Translated ENG → UK English
🇮🇳 South Indian Markets: Hindi → Telugu · Hindi → Tamil · English → Tamil · Tamil → Malayalam · Hindi → Malayalam
🌎 LATAM: English US → Neutral Spanish
🇮🇹 Italy: German → Italian
The pipeline extracts every character and entity from the source text, resolving coreference across hundreds of chapters. It generates a cultural transposition strategy before changing a single name. Characters are localized first, then entities in graph-segmented batches that preserve semantic relationships. A validation pass catches naming conflicts and fills gaps surgically, regenerating only what’s missing. Finally, each chapter is adapted in parallel, names replaced, cultural references transposed, prose reshaped for the target audience. Source language, source culture, target language, and target culture are config parameters. The architecture handles the rest.
Within 6 months of the market launch in Germany, we started facing a pressing demand for more content from the market. We had 12 shows running in the Professionally Generated Content [PGC] workflow and it was abundantly clear that there was a need for far more shows in more genres for the market to continue growing.
Leveraging the Adaptation workflow, we were able to launch a further 36 shows within 4 months to increase the content pool both in width (number of shows/genres) and depth (available hours of content).
This sudden increase in content sufficiency also came through in some tangible metrics, including a significant increase in platform playtime, and also increasing revenue contributions month-on-month from the AI Adaptation shows without cannibalizing the PGC shows. We are also now using this workflow to test shows before commissioning them for full production.
The scale of the Adaptation workflow is already reflected in tangible business outcomes: 600+ AI-adapted show launches across diverse genres such as Drama-Romance, Crime, Fantasy and Romantasy; successful expansion across 8 language markets, including the US, UK, Europe, and LATAM, and $20.5M+ in lifetime revenue. We have also successfully launched Devnagri Hindi Adaptation and are now in the process of expanding into South Indian languages, markets that are especially significant because general-purpose LLMs have traditionally performed less reliably there.
Try Atlas in the playground here .