In a content-rich world, user-generated comments play a pivotal role in enhancing social engagement and platform stickiness. On audio-first platforms like ours, where users binge listen to long hours of content, the comments section becomes a place where listeners react, critique and empathize with it.
But ranking these comments meaningfully is non-trivial. Traditional comment ranking systems, often based on simple heuristics, tend to be shallow in capturing semantic alignment with the content. Systems that can account for the narrative context and not just surface-level signals, can vastly improve user engagement.
Thus, at Pocket FM, we took on the challenge to revamp our comment ranking system, optimizing for relevance, engagement and emotional depth - while taking into account compute and scalability.
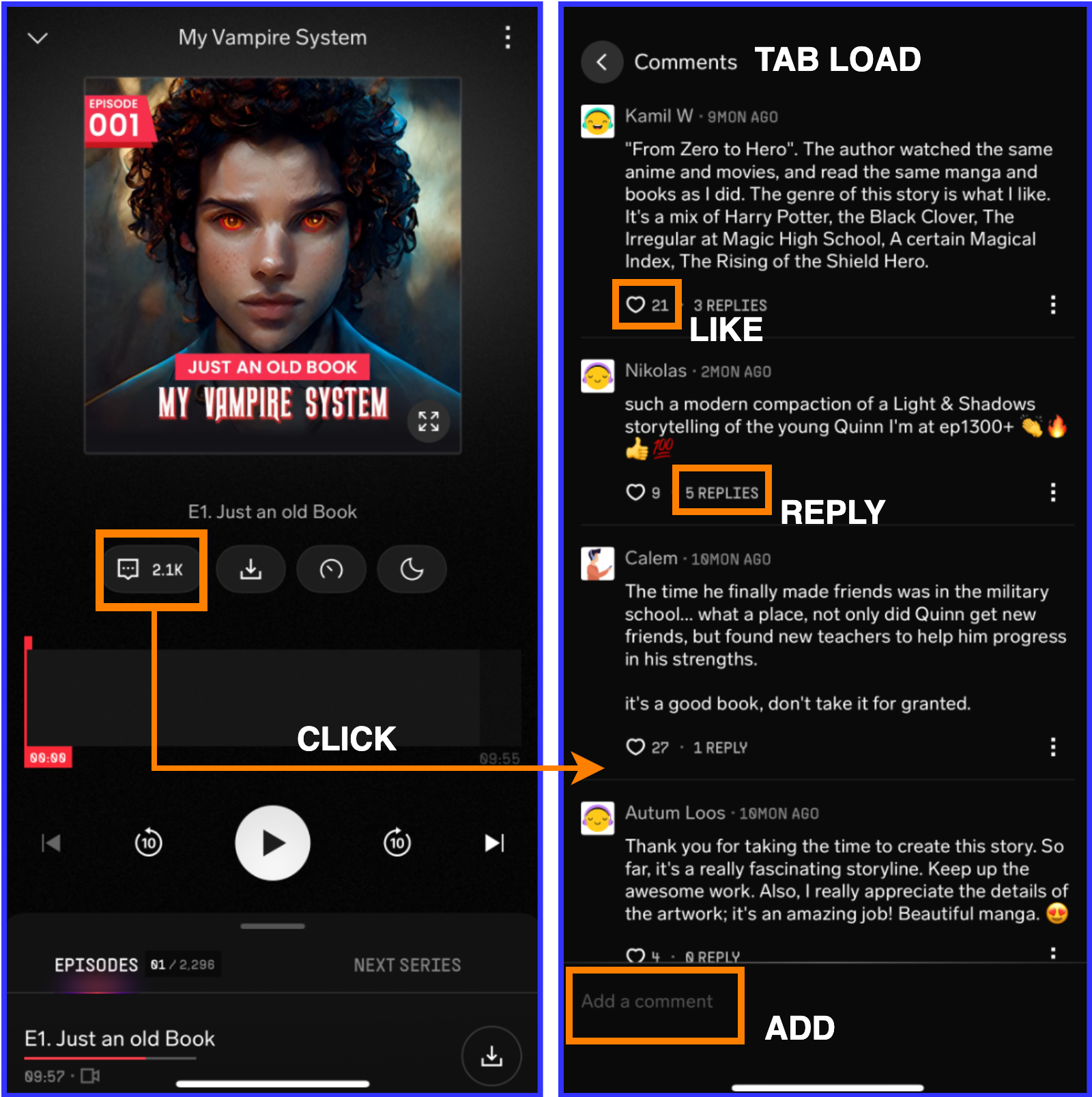
Figure: Comments Interface and Different User Signals of the Comments Funnel Each show has multiple episodes on our platform and each of them can receive thousands of comments, many of which have little to no connection with the actual story arc or episode progression. Some are primarily spams, some transactional, while a few are genuinely insightful, they often remain buried deep. So the challenge is essentially, how can we automatically identify and surface comments that are meaningful with respect to the specific episode? This required designing a pipeline that could understand and answer the following questions:
What is the episode about? (Semantics)
What is the tone of the comment? (Tone and Emotion)
How engaging the comment is? (Likes, Replies)
Whether it is a quick reaction or a deeper reflection? (Length)
The core of our pipeline is understanding whether a comment aligns semantically with the episode’s content. We use episode level script as a reference point to assess the context. However, working with full scripts posed challenges due to token length constraints in most offline embedding models. We addressed this by prompting Claude 3.5 Sonnet to generate a short, crisp summary of each episode. The prompt was explicitly designed to capture the key events and plot points, highlight the main characters involved, and remain under 500 tokens to ensure compatibility with downstream embedding models. The max token cap was critical since most efficient offline models support a maximum input length of 512 tokens. Staying within this limit ensured we could reliably generate embeddings without truncation or performance degradation.
Post that, we generate embeddings using the openly available General Text Embeddings (GTE-small) model by Alibaba, a general-purpose unified sentence transformer optimized for speed and accuracy. Comments and summaries are both embedded (dim = 384), and cosine similarity is computed between each comment and the corresponding episode summary. Final scores are normalized within an episode to keep the values interpretable. From this, we derive Ssemantic, the semantic similarity score of the comment. This score allows us to elevate comments that “talk about what just happened.”
Comments carry emotional weight, whether it’s excitement, sarcasm, curiosity or critique. While signals like engagement tell us how popular a comment is, tone helps capture how a comment feels. To add this emotional layer, we use a pretrained lightweight multilingual model trained on social media conversations to detect the expressive tone of each comment. Rather than rigidly classifying comments as ‘positive’ or ‘negative’, we use this model to identify high-confidence, emotion-rich expressions that may resonate more deeply with listeners. These are gently factored into the overall score to surface a diverse and engaging mix of comments, without overriding more grounded signals like relevance or effort. This gives us Stone for a comment.
Engagement on a comment matters, but it can be misleading alone. A funny or shallow comment might get abundant likes/replies, but adds little value to the discussion. Still, we include it as a signal. We normalize the count of likes and replies per episode and apply winsorization to avoid outliers. Then, they are combined with different weights, with replies getting a slightly higher weight as they imply a more stronger engagement. By this, we get Sengagement = wlike * SLike + wreplies * SReplies subject to the constraint wlike + wreplies = 1.
Longer comments tend to be more reflective and explanatory, though not always better. Still, length acts as a proxy for additional effort done on part of the user. We apply winsorization to eliminate outlier inflation and normalize for further combination, giving us Slength.
The final score is simply a weighted combination of the above scores as follows -
Score = w1 * Ssemantic + w2 * Stone + w3 * Sengagement + w4 * Slength
Subject to the constraint w1 + w2 + w3 + w4 = 1 and wi ∈ [0, 1]
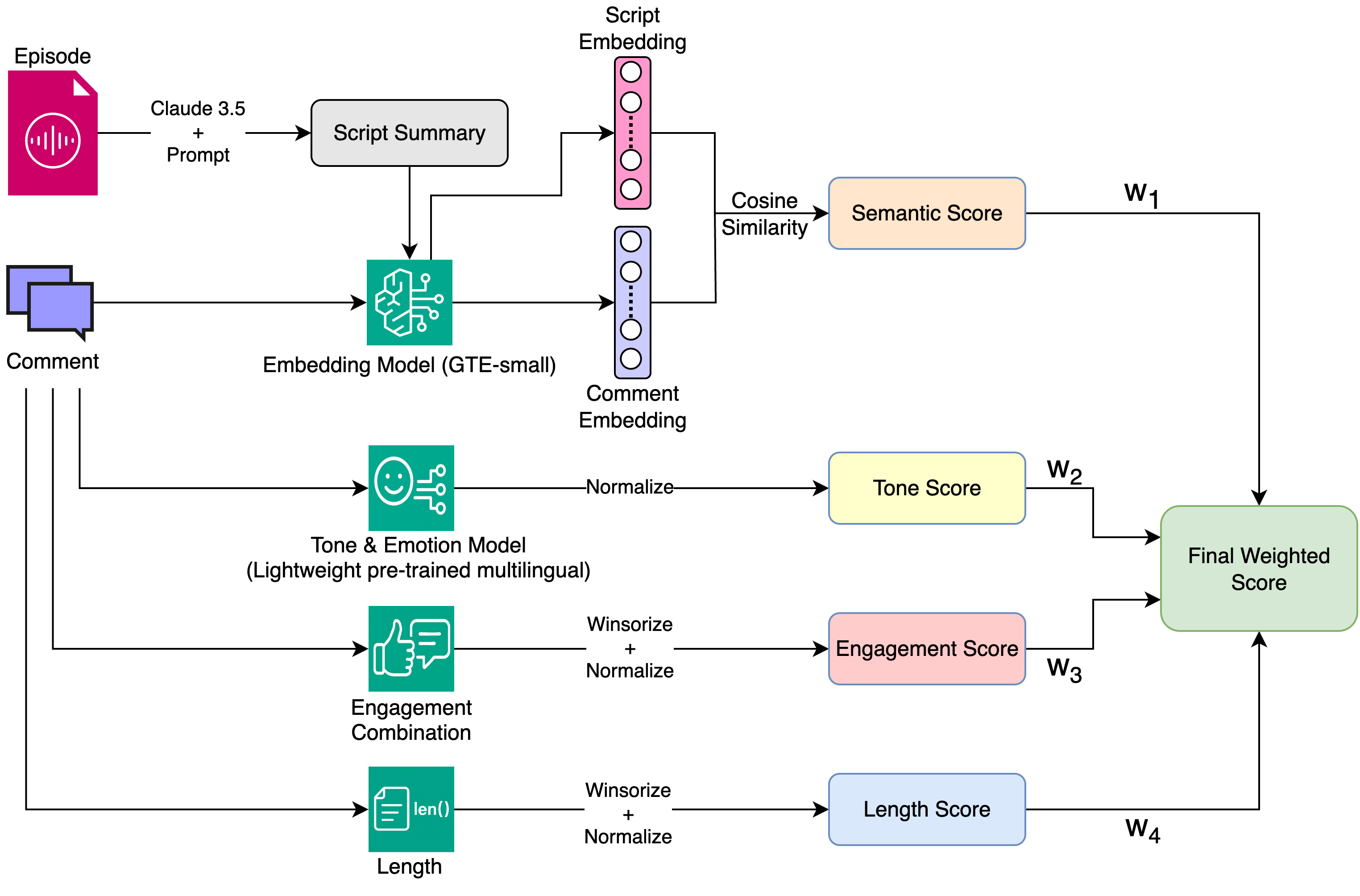
Figure: Overall Pipeline for Single Episode and Comment
While our scoring pipeline forms the core foundation, deploying it in a production environment requires a dynamic and resource-efficient architecture. Both the content and the user interactions on the platform evolve continuously which makes a static system infeasible.
New episodes are regularly released across shows. Since comment relevance relies on semantic alignment with the episode content, we cannot solely depend on a precomputed summary corpus. Each new episode triggers a sub-pipeline that- extracts the full episode script, summarizes it, embeds the summary and stores the generated embeddings for downstream comment similarity scoring. This automation ensures that the comment ranking system has timely semantic context available for every episode.
User comments are not immutable, they may be newly posted, edited, or continue to accumulate user engagement signals such as likes and replies over time. To maintain relevance:
Every new comment is embedded and scored against the latest episode summary, including tonal, length, and initial engagement signals.
Edited Comments triggers re-embedding computation and full re-scoring to reflect updated text content.
Engagement Shift: Likes and replies per comment are tracked and updated affecting the composite score.
Any meaningful drift due to these triggers a re-evaluation of the final weighted score. These changes mean that episode level normalization can also affect the scores for all comments within that episode. To minimize overhead resulting from this, we compare the old and new scores of a comment and only push updates to the stream if the change is significant enough to alter its relative ranking in the episode. This avoids redundant writes or downstream computation. This incremental strategy ensures both freshness and scalability, making our comment ranking system robust in production.
To evaluate the efficacy of the ranking, we ran an A/B experiment comparing:
Variant A : Control (legacy ranking)
Variant B : New ML based ranking using the composite score
The experiment was run on a subset of top N English shows to ensure high comment volume and engagement.
While overall platform-level metrics remained neutral to slightly positive, we saw clear improvements in comment-specific funnel metrics, indicating better engagement with the ranked comments. Specifically, metrics like Comment Tab Click Rate showed +4.57% and Comment Tab Load Rate +3.11% statistically significant relative lift compared to control. Comments Added and Comments Liked also showed positive trends of +4.01% and +2.33% relative lift respectively. These gains validate our hypothesis that a context-aware, semantic-first ranking system leads to better user interaction in the comment section.
This has laid the groundwork for intelligent, episode-aware comment ranking, but we view it as just the beginning. One of our upcoming priorities will be to expand this system to other regional languages which will require not only a better summarization and embedding model but also more culturally nuanced tonal analysis.
We will also be exploring ways to personalize the comment ranking experience. For instance, a new user just starting a show may benefit from seeing explanatory or spoiler-free comments, while a returning user might prefer emotional discussions or plot theories. Introducing such personalization could significantly improve the reader-comment interaction.
As generative models evolve and our content library grows, we are highly motivated to build a comment system that matches the depth and richness of the stories themselves.