In the fast-evolving world of platforms like Pocket FM, understanding why a user is engaging with content is just as important as what they are listening to. Whether a user is casually browsing for new shows, deeply engaged in a binge session, or returning after a break, each behavior reflects a unique intent. Accurately predicting these intents—such as discovery, exploration, or re-engagement—allows Pocket FM to deliver highly personalized content recommendations, optimize user experience, and drive long-term retention.
By moving beyond surface-level metrics like play counts or clicks, an intent prediction model enables the platform to understand the underlying goals of users. This, in turn, powers smarter content delivery strategies—from surfacing new shows to nudging users toward completion of long-format stories. In a space where content is abundant and user attention is limited, modeling user intent is critical to standing out and staying relevant.
User behavior on Pocket FM unfolds over time—whether it's a user sampling a few episodes, skipping through subgenres, or returning to a long-form story after a break. These patterns are inherently sequential. Traditional models that treat each interaction independently often miss the evolving context behind user actions. In contrast, sequential models, like those built on Transformer encoders, excel at capturing temporal dependencies and evolving user preferences.
Transformers, in particular, are well-suited for this task due to their ability to model long-range dependencies without the limitations of traditional RNNs or LSTMs. By attending to the recent history of user actions, they can identify subtle patterns—like a gradual shift in show preferences or a build-up to binge behavior—that are critical for accurately predicting user intent. This leads to more nuanced, context-aware predictions that improve both personalization and user satisfaction on the platform.
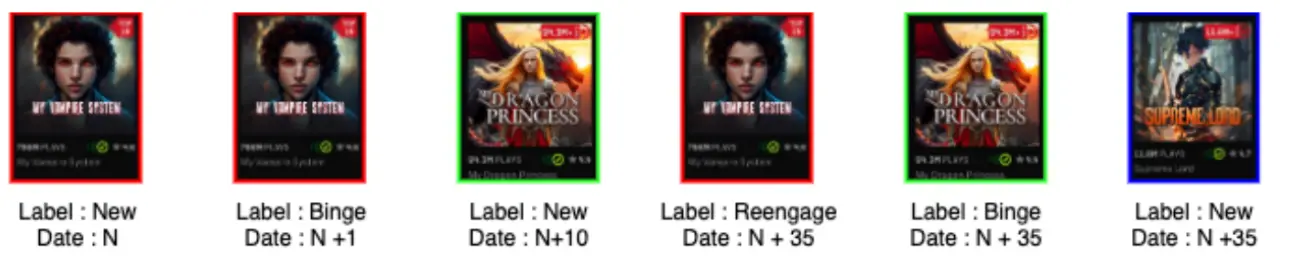
To effectively model user intent, we construct sequential histories of listening behavior, capturing the evolving interaction pattern of each user. Each event in the sequence represents a listening session in a day associated with a particular show, along with metadata such as the label tag (intent label like New, Binge, Reengage) and the timestamp (relative date, e.g., N, N+1, N+10, etc.).
As illustrated above, the sequence reflects the user's journey:
On Day N, the user starts a new show (My Vampire System)—tagged as New.
On Day N+1, they continue the same show—now tagged as Binge, showing sustained engagement.
On Day N+10, the user starts a different show (Dragon Princess)—again marked New, indicating exploration.
A gap of 25 days follows i.e N+35, the user returns to My Vampire System after more than 30 days, this interaction is tagged Reengage, signaling a comeback on My Vampire System.
On the same day (N+35), the user's activity on Dragon Princess is tagged as Binge, a show the user already engaged with within the past 30 days. And listening to a completely new show ex- Supreme Lord, is tagged a New.
Along with the types of listening or label, we track a bunch of other numerical features on listening level i.e Playtime, Number of episodes listened, Show completion fraction and categorical features like Source screen, Source Module etc to name a few. Also at the time of training data preparation we calculate the number of days since the last listen of the show.
Apart from the sequential features, there are other sets of features that remain static for a given user, like locale , age, spending behaviour, etc have been used in the model.
Based on the above sequence, we predict three targets independently.
New: Listening to a completely new/unexplored show for a user
Reengage: Listening to a show which has not been listened to in the last 30 days.
Binge: Listening to a show which has been listened to in the last 30 days.
The definition of Re-engage and Binge has been chosen because of long format content. It can be tweaked with any other definition.
We don't define a user by a single state because a user can be listening to multiple shows in parallel. So at the same time, they can be in all three states i.e. New, Reengage and Binge. Having only one state would result in loss of information.
The training data is built on user x date level. So for any given day the model looks at the past interactions before that day and labels are generated based on the same day interaction. Therefore only the users who have interacted on a given day have been considered during the training session.
We experimented with different numbers of interactions to consider while creating the sequence. But we found that 10 interactions are enough to capture the interest. Any user having less than 10 interactions at that point of time is padded with an unknown token of corresponding categories.
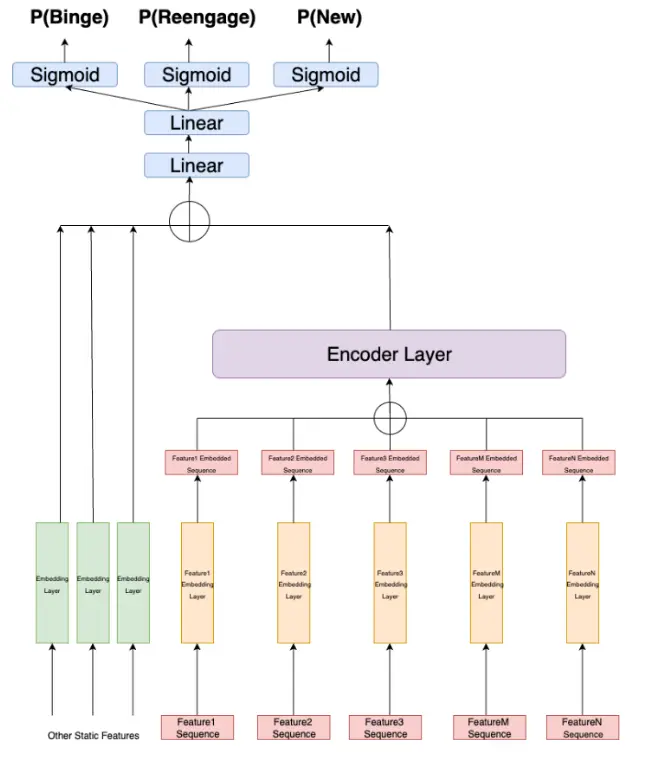
We convert all the numerical features into categorical features using bucketization methods. And Positional encoding is learnt to capture the order of interactions.
All the categorical features are embedded and summed for each timestep, forming the input to a Transformer Encoder, which models the relationships across the sequence through self-attention. The aggregated sequence output is then combined with static user features and passed through a multi-layer perceptron (MLP). Finally, three separate output heads predict intent labels simultaneously for different behavioral aspects.
Since the model predicts multiple intent labels (multi-task setting), each target can have a different class imbalance. To address this, the training loop dynamically computes a positive class weight (pos_weight) for each target using the actual label distribution in the batch.
Each target then uses its own BCEWithLogitsLoss loss function, weighted appropriately to penalize underrepresented classes more strongly. This ensures that the model doesn't get biased toward majority labels and learns to detect rare intents like Re-engage/new effectively.
The model has been evaluated by looking at the ML metrics like ROC AUC, F1 score for each set of targets. Apart from that, we evaluated the model offline to see if it has been able to differentiate between the binge and non binge users. So we looked at the users and their model predictions who actually binged on a given day vs the users who didn’t binge on that day. And we see there is a significant gap in the probabilities between them. This remains true for reengage and new shows intention as well.
We are actively exploring different architectures, redefining our labels and at the same time finding different signals which indicate user behaviour. At the same time all of our training data is biased with existing model ranking so debiasing plugged in with this model is an interesting research direction we are continuously exploring.